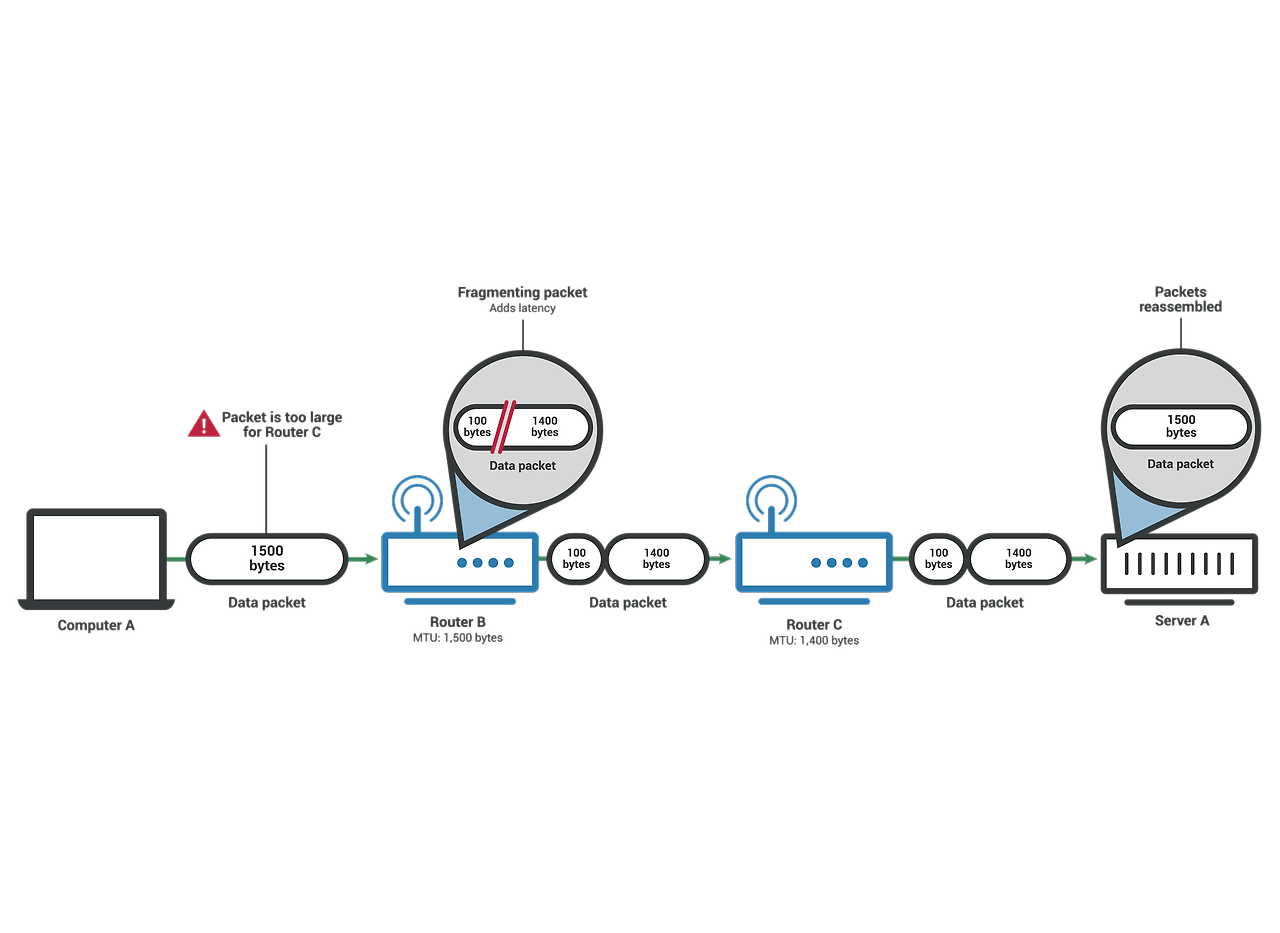
패킷을 전송할 때 MTU(Maximum Transmission Unit)을 초과하면 한번에 전송할 수 없어 패킷을 MTU 이하의 조각으로 분할하는 것을 단편화(Fragmentation), 분할된 조각을 단편(Fragment)이라고 한다.
거치는 라우터 마다 전송에 적합한 데이터 링크 계층 프레임으로 변환이 필요하다.
재조립(Reassembly)은 항상 최종 수신지에서만 가능하다.
IPv4 단편화
IPv4에서는 발신지 뿐만 아니라 중간 라우터에서도 IP 단편화가 가능하다.
각 조각들은 최종 목적지 시스템에 전달되기 전에는 재조립되지 않고, 최종 목적지에 전달되면 목적지 시스템의 IP 소프트웨어가 원래의 데이터그램으로 재조립 됨
IPv6 단편화
IPv6에서는 IP 단편화가 발신지에서만 가능하다.
IPv6에서는 라우팅 처리 효율을 높이기 위해, 가급적 IP 단편화를 필요없도록 한다.
Ipv4와 달리, 기본 헤더 상에 단편화 제어 관련 필드를 두지 않고, 단편화 확장 헤더를 통해 단편화한다.
MTU(Maximum Transmission Unit)
MTU는 최대 전송 단위로서 TCP/IP Network 등과 같이 패킷 또는 프레임 기반의 네트워크에서 전송될 수 있는 최대 크기의 패킷 또는 프레임을 가리키며 대개 옥텟을 단위로 사용한다.
MTU가 너무 크면 큰 크기의 패킷을 처리할 수 없는 라우터를 만나면 재전송을 해야하는 경우가 생길 수 있다.
MTU가 너무 작으면 상대적으로 헤더 및 송수신 확인에 따르는 오버헤드가 커진다
단편화 피하기
IP의 본래 목적은 주소 지정과 단편화지만 오늘날의 네트워크 환경에서는 잘 발생하지 않는데, 이는 네트워크 성능의 발전 때문도 있지만 단편화가 잦으면 불필요한 트래픽 증가와 대역폭 낭비를 초래할 수 있기 때문이다. 혹은 단편화된 패킷을 재조립하는 과정에서 발생하는 부하도 성능 저하로 이어질 수 있다.
단편화 피하는 방법
IP 패킷을 주고받는 경로에 존재하는 모든 호스트의 처리 가능한 MTU 크기를 고려해서 IP 단편화 없이 주고 받을 수 있는 크기만큼만 전송해야 함
IP 단편화 없이 주고 받을 수 있는 크기 = 경로 MTU(Path MTU)
주고받을 수 있는 경로 MTU를 구해서 해당 크기만큼만 송수신하여 IP 단편화를 회피하는 기술을 경로 MTU 발견(Path MTU discovery) 라고 함
오늘 날의 네트워크는 경로 MTU 발견을 지원하고 처리 가능한 최대 MTU 크기도 균일하여 IP 단편화가 자주 발생하지 않게 됨.
IP 주소
IP 주소는 어느 네트워크의 어느 호스트라는 것을 식별하는 주소입니다. IP 주소는 호스트가 속한 네트워크 주소/브로드캐스트 주소인 네트워크 부(Network Part 또는 Network ID)와 호스트의 주소인 호스트 부 (Host Part 또는 Host ID)로 구성됩니다.
네트워크 부는 어떤 네트워크 인지를 나타내 다른 네트워크와 구분하는 역할을 하고, 호스트 부는 해당 네트워크의 어느 호스트인지를 나타내 다른 호스트와 구분하는 역할을 합니다. 여기서 호스트는 컴퓨터뿐만이 아니라 IP 주소가 할당되는 라우터를 포함합니다.
네트워크 부는 인터넷에 접속되어 있는 모든 네트워크 중에서, 호스트 부는 그 호스트가 속한 네트워크 내에서 유일한 번호를 할당하여 인터넷 전체에서 동일한 IP 주소를 갖는 호스트는 1대밖에 없도록 설정합니다.
따라서 같은 네트워크 안에 있는 컴퓨터, 즉 라우터 없이도 데이터 전송이 가능한 컴퓨터는 네트워크 부가 동일하고 호스트 부만 다릅니다. 달리 말하면 네트워크 부가 다르다는 것은 서로 다른 네트워크라는 의미이고, 라우터를 통하지 않고는 통신이 불가능하다는 뜻입니다. 서로 다른 네트워크가 라우터를 통해 통신이 가능한 것은 라우터가 IP 주소의 네트워크 부를 보고 라우팅을 하여 데이터를 전송하기 때문입니다.
인터넷에 접속 가능한 네트워크를 만들기 위해 IP 주소 할당 기관(NIC)에 IP 주소 할당을 신청하면 할당 기관에서는 네트워크 부까지만 할당합니다. 네트워크 부를 할당받으면 네트워크를 만드는 사람(네트워크 관리자)이 호스트 부를 결정하여 네트워크 부와 호스트 부를 합친 IP 주소를 개별 호스트에 설정하는 것입니다.
IPv4 도입 초기에는 클래스(class)를 기준으로 네트워크부와 호스트를 나누는 방식을 사용했지만, 클래스 방식의 비효율성으로 인해 현재는 클래스에 구애받지 않고 서브넷 마스크(subnet mask) 방식을 사용하고 있습니다.
IP 주소의 클래스
클래스 기준은 IP 주소를 앞에서 8비트씩 나눈 그룹을 조합하여 네트워크 부와 호스트 부를 정한 것입니다. 즉, 클래스에 따라 어디까지가 네트워크 부이고, 어디까지가 호스트 부인지가 결정됩니다.
① 클래스 A
클래스 A는 IP 주소 32비트 중 앞 8비트를 네트워크 부로, 다음 24비트를 호스트 부로 나눈 것입니다. 네트워크 부의 첫 비트는 클래스 A 식별 비트인 '0'이 할당되기 때문에 00000000 ~ 01111111의 번호가 네트워크 부로 사용됩니다. 이를 십진수로 표기하면 클래스 A의 네트워크 부는 0 ~ 127의 번호가 할당됩니다.
다음 24비트는 호스트 부로 사용되고, 한 네트워크 안에서 할당할 수 있는 호스트 번호는 0.0.0 ~ 255.255.255까지 약 16,777,214개입니다. 말하자면 IP 주소 관리기관이 IP 주소 신청자에게 클래스 A의 네트워크 부 1개를 할당하면, 신청자는 약 1,677만 개의 호스트 부를 마음대로 정할 수 있게 되는 것입니다. 1개의 네트워크에 약 1,677만 개의 호스트를 연결할 수 있기 때문에 클래스 A는 주로 대규모의 네트워크를 구축하는 기관에 할당됩니다.
호스트 부의 모든 비트가 0과 1인 번호는 특수 목적(네트워크 주소와 브로드캐스트 주소)으로 사용하기 때문에 IP 주소의 호스트 부를 할당하는 경우에는 이 두 번호를 제외합니다. 따라서 클래스 A의 호스트 부에서는 2의 24승인 16,777,216에서 2를 뺀 16,777,214개의 번호를 호스트 부에 할당할 수 있습니다.
네트워크 부와 호스트 부를 조합해 클래스 A에서 할당 가능한 IP 주소의 범위는 0.0.0.0 ~ 127.255.255.255이고, 이는 2,147,483,648(2의 31승) 개로 전체 IP 주소의 개수 중 약 50%에 해당합니다.
② 클래스 B
클래스 B는 IP 주소 32비트 중 앞 16비트를 네트워크 부로, 다음 16비트를 호스트 부로 나눈 것입니다. 네트워크 부의 맨 앞 2비트는 클래스 B의 식별 비트인 '10'으로 할당되기 때문에 10000000 ~ 10111111의 번호가 네트워크 부의 첫 8비트로 사용됩니다. 네트워크 부 16비트를 십진수로 표기하면 클래스 B의 네트워크 부는 128.0 ~ 191.255 번호가 할당됩니다.
다음 16비트는 호스트 부로 할당되고, 한 네트워크 안에서 할당할 수 있는 호스트 주소는 65,534(2의 16승 - 2) 개입니다.
네트워크 부와 호스트 부를 조합해 클래스 B에서 할당 가능한 IP 주소의 범위는 128.0.0.0 ~ 191.255.255.255이고, 이는 1,073,741,824(2의 30승) 개로 전체 IP 주소의 개수 중 약 25%에 해당합니다.
③ 클래스 C
클래스 C는 IP 주소 32비트 중 앞 24비트를 네트워크 부로, 다음 8비트를 호스트 부로 나눈 것입니다. 네트워크 부의 맨 앞 3비트는 클래스 C의 식별 비트인 '110'으로 할당되기 때문에 11000000 ~ 11011111의 번호가 네트워크 부의 첫 8비트로 사용됩니다. 네트워크 부 24비트를 십진수로 표기하면 클래스 C의 네트워크 부는 192.0.0 ~ 255.255.255 번호가 할당됩니다.
다음 8비트는 호스트 부로 할당되고, 한 네트워크 안에서 할당할 수 있는 호스트 주소는 254(2의 8승 -2) 개입니다.
네트워크 부와 호스트 부를 조합해 클래스 C에서 할당 가능한 IP 주소는 192.0.0.0 ~ 223.255.255.255입니다.
네트워크 주소와 브로드캐스트 주소
네트워크 1의 호스트나 라우터는 203.179.33.0이나 203.179.33.255의 IP 주소를 사용할 수 없습니다. 마찬가지로 네트워크 2의 호스트나 라우터도 192.168.24.0이나 192.168.24.255의 IP 주소를 사용할 수 없습니다. 다시 말해 클래스 C인 경우 호스트 부 8비트가 모두 0, 즉 십진수로 0인 번호와 호스트 부 8비트가 모두 1, 즉 10진수로 255인 번호는 컴퓨터나 라우터가 자신의 IP 주소로 사용할 수 없습니다.
클래스를 불문하고 IP 주소 중 호스트 부의 모든 비트가 0인 번호는 네트워크 주소로, 모든 비트가 1인 번호는 브로드캐스트 주소라는 특수 목적으로 사용하기 때문에 호스트와 라우터에는 할당하지 않습니다.
네트워크 주소는 전체 네트워크에서 작은 네트워크를 식별할 때 사용되고, 호스트 부가 십진수로 0이면 그 네트워크를 대표하는 주소가 됩니다.
브로드캐스트 주소는 하나의 네트워크에 있는 모든 호스트에 동시에 데이터를 보낼 때 사용되는 전용 IP 주소를 의미합니다.
즉, 전체 네트워크에 데이터를 전송할 때는 호스트 부에 255를 설정하면 됩니다. 만약 IP 주소 203.179.33.13인 호스트가 IP 주소 192.168.24.255로 데이터 를 전송하면 192.168.24.0의 네트워크에 있는 모든 호스트가 데이터를 수신합니다.
서브넷팅과 서브넷
클래스 기반 주소 지정 방식에서는 클래스가 정해지면 네트워크 부와 호스트 부의 길이 및 하나의 네트워크 당 사용 가능한 IP 주소가 정해집니다.
클래스 A를 사용할 경우 한 개의 네트워크 당 약 1,677만 대의 호스트를 연결할 수 있고 클래스 B를 사용할 경우 한 개의 네트워크 당 약 6만 5천대의 호스트를 연결할 수 있습니다. 하지만 실제로 이렇게 많은 호스트를 하나의 네트워크에 연결하는 경우는 거의 없기 때문에 전체 IP 주소의 75%를 차지하는 클래스 A와 클래스 B에서 많은 수의 IP 주소가 사용되지 않고 낭비됩니다.
IP 주소를 효율적으로 활용하기 위해서 클래스 A와 B 같은 대규모 네트워크를 좀 더 작은 네트워크로 분할하는 것을 서브넷팅(Subnetting)이라 하고, 분할된 네트워크를 서브네트워크(Subnetwork) 혹은 줄여서, 서브넷(Subnet)이라고 합니다.
네트워크 부가 0인 클래스 A의 네트워크 1개를 서브넷팅 하여 256개의 작은 네트워크로 분할한 것입니다. 호스트 부의 비트를 서브넷 부로 변경하여 서브넷으로 만듭니다. 서브넷팅을 하면 네트워크 부와 호스트 부로 구성되었던 클래스가 네트워크 부, 서브넷 부, 호스트 부로 변경됩니다.
약 1,667만 대의 컴퓨터를 연결할 수 있던 하나의 네트워크를 256개의 서브넷으로 분할하여 하나의 서브넷에 약 6만 5천 대의 컴퓨터를 연결할 수 있게 만든 것입니다.
서브넷팅이라는 논리적인 방법으로 분할된 네트워크는 라우터에 의해 물리적으로 구별됩니다.
서브넷팅 전에는 라우터 없이 약 1,667만 대의 컴퓨터 간에 통신이 가능했지만, 서브넷팅 후에는 서브넷이 서로 통신을 하기 위해선 라우터가 필요합니다.
이처럼 서브넷팅을 통해 호스트 부가 서브넷 부로 변경되면서 네트워크 부가 확장됩니다. 따라서클래스 A의 IP 주소를 서브 넷팅하면 네트워크 부가 변경되는데 IP 주소만으로는 변경된 네트워크 부가 어디까지인지 알 수가 없습니다. 아래 <그림 8>과 같이 서브넷팅을 한다고 해서 IP 주소가 변경되지 않기때문입니다.
IP 주소만으로 네트워크 부와 호스트 부의 경계를 알 수 있도록 만든 클래스가 서브넷팅으로 인해 그 의미를 잃게 된 것입니다.
따라서 IP 주소를 서브넷팅하는 경우 IP 주소와 별도로 어디까지가 네트워크 부이고 어디까지가 호스트 부인지 구별할 수 있는 식별자가 필요한데, 이 식별자를 서브넷 마스크라고 합니다.
서브넷 마스크
서브넷 마스크는 IP 주소의 네트워크 부와 호스트 부의 경계를 식별하기 위해 만든 숫자입니다. 서브넷 마스크는 IP 주소의 32비트에 대응한 32비트로 구성되어 있습니다. 즉, 서브넷 마스크는 IP 주소처럼 32개의 0 또는 1로 구성된 값입니다.
IP 주소의 비트가 네트워크 부이면 이 비트에 대응하는 서브넷 마스크의 비트는 1이 되고, IP 주소의 비트가 호스트 부이면 서브넷 마스크의 비트는 0이 됩니다. 이러한 방법으로 클래스에 구애받지 않고 IP 주소의 네트워크부를 식별할 수 있습니다.
서브넷 마스크 표기법
① 십진수 표기법
32비트로 표현된 서브넷 마스크도 IP 주소와 마찬가지로 보기 쉽게 전체 32비트를 8비트씩 4그룹으로 나누어, 각 그룹을 십진수로 변환하고, 그룹의 경계에 '.'을 넣은 방법으로 표기하고 있습니다.
② 프리픽스 표기법
서브넷 마스크를 슬래시(/)와 네트워크부 비트수로 나타내는 프리픽스(prefix) 표기법을 사용할 수 있습니다. 프리픽스로 표기한 서브넷 마스크는 IP 주소와 함께 묶어 표현합니다.
네트워크 부가 8비트인 클래스 A에서 8비트를 서브넷팅한 IP 주소를 서브넷 마스크로 정의
서브넷팅 후 IP 주소는 동일하지만 달라진 서브넷 마스크로 서브넷팅 후에는 앞에서 16비트까지가 네트워크 부인 것을 식별할 수 있게 됩니다.
서브넷 마스크의 유용성
서브넷 마스크를 사용하면 8비트 단위가 아닌 1비트 단위로 네트워크 부를 구성할 수 있기 때문에 더 세분화된 네트워크를 만들 수 있습니다.
예를 들어, 약 60개의 호스트를 연결하는 네트워크를 구축하는 경우 클래스 기준에서는 가장 적은 수의 호스트를 연결할 수 있는 클래스 C의 네트워크 부를 사용할 수밖에 없습니다. 다시 말해 60개의 호스트를 연결하는 하나의 네트워크를 만들기 위해 IP 주소 관리 기관에 IP 주소 할당 신청을 하면 주소 관리 기관에서는 C클래스의 네트워크 부 주소 하나를 할당하게 되고 신청자는 254(2의 8승 - 2) 개의 IP 주소를 사용할 수 있게 됩니다. 60개가 필요한 데 254개가 할당되니 나머지 IP 주소는 누구도 사용하지 못하는 주소가 됩니다.
만약 호스트 부에서 2비트를 빌려 서브넷팅 하면 클래스 C의 1개의 네트워크를 4개로 분할하고 각 네트워크 당 62(2의 6승 -2)의 IP 주소를 사용할 수 있게 됩니다. 따라서 60개의 IP 주소가 필요한 사람에게 서브넷 마스크가 255.255.255.192인 IP 주소의 네트워크 부 주소 하나를 할당하고, 나머지 3개의 네트워크 부 주소를 다른 사람에게 할당하는 방법으로 IP 주소를 낭비하지 않을 수 있습니다.
현재는 클래스와 상관없이 한네트워크에 연결하고 싶은 호스트들의 규모에 맞게 네트워크 부와 호스트 부의 길이를 비트 단위로 유연하게 변경할 수 있는 서브넷 마스크를 사용하여 IP 주소를 할당합니다.
클래스 방식에서 네트워크 부를 8비트 단위로 IP 주소 32비트의 맨 앞에서부터 선택한 것처럼 서브넷 마스크 방식에서도 네트워크 부를 1비트 단위로 IP 주소 32비트의 맨 앞에서부터 차례로 선택합니다. 따라서 서브넷 마스크는 반드시 연속한 '1' 과 연속한 '0' 으로 구성됩니다. '1'과 '0'이 교대로 나타나는 서브넷 마스크는 없습니다.이로 인해 서브넷 마스크의 십진수 표기법이 가질 수 있는 값은 다음과 같습니다.
NAT와 NAPT
인터넷이 보편화되면서 IP 주소의 부족 문제를 해결하고, 네트워크 보안을 강화하기 위해 다양한 기술이 개발되었습니다. 그 중에서 NAT(Network Address Translation)와 NAPT(Network Address Port Translation)는 네트워크에서 자주 사용되는 기술입니다.
개념
NAT와 NAPT는 현대 네트워크 환경에서 필수적인 기술입니다.
NAT는 내부 네트워크의 사설 IP 주소를 공인 IP 주소로 변환하여 인터넷과 통신할 수 있게 하는 기술로 IP 주소의 절약과 보안 향상에 기여합니다.
NAPT는 NAT의 확장 개념으로, 단순히 IP 주소를 변환하는 것에 더해 포트 번호까지 함께 변환합니다. 이를 통해 하나의 공인 IP 주소를 사용하여 다수의 내부 네트워크 장비들이 동시에 인터넷에 접속할 수 있습니다. 다수의 장치가 동시에 인터넷에 접속할 수 있게 합니다
NAT
특징
사설 IP 주소를 외부에서 감출 수 있음.
IP 주소의 재사용이 가능해, 공인 IP 주소의 사용을 줄일 수 있음.
네트워크 보안을 강화할 수 있음.
장점
공인 IP 주소의 절약.
내부 네트워크 구조를 외부에 노출시키지 않음으로써 보안 강화.
단점
네트워크 연결에 있어 일부 프로토콜과의 호환성 문제가 발생할 수 있음.
특정 애플리케이션에서 문제가 발생할 수 있음.
사용 사례
소규모 가정용 네트워크나 중소기업에서 내부 네트워크 보호 및 IP 주소 절약을 위해 널리 사용됩니다.
NAPT
개념
NAPT는 NAT의 확장 개념으로, 단순히 IP 주소를 변환하는 것에 더해 포트 번호까지 함께 변환합니다. 이를 통해 하나의 공인 IP 주소를 사용하여 다수의 내부 네트워크 장비들이 동시에 인터넷에 접속할 수 있습니다.
특징
IP 주소와 포트 번호를 모두 변환함으로써, 여러 장치가 동시에 하나의 공인 IP 주소를 공유할 수 있음.
어원은 그물을 뜻하는 net과 work의 합성어이며 그물을 짜는 행위를 가리키는 명사에서 임의의 연결망을 지칭하는 용어로 그 범위가 확장된 단어이다. 또한 통신 장치 간에 데이터 및 정보를 교환하는 것을 의미한다. 정보를 교환하기 위해서는프로토콜(Protocol)이라는 통신 규약에 따라 정보를 전송하고 공유한다.
네트워크 통신의 발달로 전세계 소식을 실시간으로 확인하고, 정보를 교류할 수 있게 되었으며, 사물 인터넷(IoT)기기의 발달과 보급으로 다양한 전자 기기들을 제어할 수 있게 되었다.
네트워크 통신의 역사
1800년경
유선 통신의 시작
볼타가 최초로 전지를 발명하여 전선을 통해 신호를 보내는 방법을 연구하기 시작
사무엘 모르스가 알파벳 문자에 대해 점과 대시를 사용해 신호를 보냈는데 이게 모스부호
1864년
무선 통신의 시작
제임스 클럭 맥스웰이 전자기파가 대기 중에서 전파된다고 예측함
1876년
알렉산더 그레이엄 벨이 음성을 전달할 수 있는 전화기를 개발
1888년
하인리히 루돌프 헤르츠가 실험을 통해 라디오파를 주고받음으로써 전자기파가 대기 중에 있다고 입증함
1894년
마르코니가 지상의 금속판에 연결된 수직 안테나를 사용해 신호 전달의 범위를 증가시킬 수 있음을 증명
해당 실험으로 121km 까지 소식 교환이 가능하게 됨
1958년
컴퓨터 통신의 시작
벨 텔레폰 연구소의 조지 스티비츠가 전화 교환회로를 산술기기로 발전시킨 모델-K 기기를 개발
모델-K가 CNC (Complex Number Calculator) 로 발전해 더 정교한 산술 계산이 가능하게 됨.
CNC는 입력기가 본체와 따로 떨어져 전화선으로 데이터를 주고받을 수 있었는데 이런 원격 데이터 통신 방식은 이후 모뎀, 시분할 시스템, 컴퓨터 네트워크 기술로 발전
1964년
군사 작전 수행을 위한 고성능 컴퓨터 개발을 목적으로 ARPA (Agency for Advanced Research Project Agency) 에 커맨드 컨트롤 리서치라는 부서를 설립
J.C.R 리클라이더에 의해 커맨드컨트롤 리서치는 순수 컴퓨터 과학 연구를 위한 IPTO(Information Processing Techniques Office)로 재탄생
1965년
세계 최초의 컴퓨터 네트워크 개발에 착수, 이 네트워크가 ARPANET (Advanced Research Project Agency Network) 탄생으로 이루어진다.
이후 최초의 장거리 컴퓨터 통신이 이루어짐. MIT 링컨 연구소의 TX-2가 캘리포니아 산타 모니카 SDC(System Development Corporation)의 Q-32 컴퓨터와 전화선으로 직접 통신함.
ARPA가 처음 시도한 장거리 컴퓨터 통신망이었다. 기존의 방대한 전화망을 이용해 컴퓨터 네트워크를 구축하려고 한 것이다. 그러나 너무 느리고 비싸고 비효율적이었다.
TX-2와 SDC Q-32 네트워크 구축을 제안한 심리학자 톰 마릴이 컴퓨터 간에 메시지를 전달하는 과정에서 메시지가 제대로 도착했는지 확인하는 방법을 가리켜 '기술적 은어' 라는 뜻으로 프로토콜이라고 부름
1967년
ARPA가 ACM 모임에서 각 호스트를 IMP라는 특정 컴퓨터에 연결하고, IMP들을 서로 연결하는 ARPANET이라는 아이디어를 제안
IMP는 현재의 라우터 개념과 유사함.
1969년
4개의 노드를 네트워크로 구성하고 NCP라는 프로토콜을 호스트 간 통신에 사용
1971년
레이 톰린슨이 전자 메일 프로그램을 개발
톰린슨이 전자 메일에 @기호를 넣었고, 지금도 이 방식에 따라 아이디 뒤에 @기호를 사용
1972년
Vinton Cerf와 Bob Kanhn이 네트워크를 통해 패킷을 전송하는 중계 하드웨어 역할을 하는 게이트웨이를 개발
1973년
빈트 서프와 로버트 칸이 TCP/IP프로토콜과 인터넷 구조를 설계
컴퓨터와 터미널로 구성되는 네트워크로 IBM의 SNA망이 최초
1974년
제록스가 이더넷을 개발
이더넷은 네트워크 구조를 호스트-터미널 구조에서 오늘날과 같은 클라이언트-서버 구조로 전환하는데 큰 역할을 함
1979년
유즈넷 탄생
1981년
TCP를 두 개의 프로토콜인 TCP와 IP로 나누고 이를 표준화
유닉스 운영체제에 TCP/IP가 배포
TCP/IP는 ARPANET의 공식 프로토콜이 됨
1983년
ARPANET에서 MILNET (군사용 네트워크)이 분리
존 포스텔이 도메인 이름 시스템을 개발
1984년
DNS가 구성되어 네트워크가 폭발적으로 확장되었다.
OSI(Open Systems Interconnection)모델, 컴퓨터 및 네트워크 모든 시스템을 상호 연동하여 사용할 수 있도록 표준화한 모델을 발표
1989년
버너스-리 라는 CERN(유럽핵물리연구소)의 물리학자가 웹 개념을 제안
1990년
ARPANET이 해체되고 NSFNET이 만들어짐
버너스-리라가 동 료인 로버트 카이유와 서로 다른 컴퓨터끼리 정보를 공유하고 서로 링크되어 찾기 쉽도록 하이퍼텍스트형태의 서비스를 도입
웹 브라우저, WWW(World Wide Web)가 등장
2007년
휴대전화와 카메라 그리고 인터넷 기능이 하나로 통합된 iPhone(스마트폰)이 등장
OSI 4계층 / 7계층
OSI 7계층
국제 표준화 기구(ISO, International Organization Standardization)
물리 계층(Physical Layer)
가장 최하위 계층으로 비트 신호를 주고받는 계층
물리적인 유무선 통신 매체(LAN, 케이블 등)을 통해 비트 스트림(BitStream)을 전송
데이터 링크 계층(Data Link Layer)
물리 계층에서는 단순히 데이터를 전달만 하기에 데이터 상에 문제가 발생하여도 알 수가 없기 때문에 같은 LAN에 속한 호스트끼리 올바르게 정보를 주고받기 위한 계층
데이터 시작과 끝 부분에 제어 정보를 추가하여 에러를 확인하고 제어
호스트를 식별할 수 있는 주소(MAC 주소) 등을 할당하여 네트워크 장비들을 식별
네트워크 계층(Network Layer)
네트워크 간 통신을 가능하게 하는 계층
데이터를 전송하는 스위칭(Switching)기능과 데이터를 전송을 위한 최적의 경로를 결정하는 라우팅(Routing)기능을 제공
네트워크 간 통신 과정에서 호스트를 식별할 수 있는 주소(IP 주소)를 이용해 다른 네트워크와 통신을 주고받기 위해 필요한 계층
전송 계층(Transfer Layer)
수신지와 목적지를 감독하면서 전체 데이터가 오류 없이 순서대로 도착하는 것을 보장하며 목적지까지 에러 제어, 흐름 제어 등을 수행하며 신뢰성 있는 데이터 전송을 담당
대표적인 프로토콜로TCP(Transport Protocol)와UDP(User Datagram Protocol)가 있다
세션 계층(Session Layer)
응용 프로그램 간의 연결 상태를 의미하는 세션(Session)을 유지하거나 새롭게 생성하고 필요하다면 연결을 끊는 역할을 하며 관리하기 위한 계층
파일을 전송하던 중에 전송이 중단되어 이어서 전송 해야 하는 경우 데이터를 동기화하고 통신 세션을 설정하고 유지하는 역할을 함.
표현 계층(Presentation Layer)
데이터를 변환, 인코딩, 압축, 암호화, 복호화 등 번역을 수행하여 상위 계층인 응용 계층이 이해할 수 있는 데이터로 가공하는 계층
대표적인 예시로 JPEG, AVI 등이 있음
응용 계층(Application Layer)
사용자와 가장 밀접하게 맞닿아 있어 통신할 수 있는 여러 응용 네트워크 서비스를 제공한다.
대표적인 예시로 웹 브라우저, FTP등이 있다
TCP/IP 모델 (OSI 4계층)
네트워크 엑세스 계층(Network Access Layer)
물리적인 연결 매체에 연결되어 패킷을 주고받는 작업을 담당
OSI 모델의 물리, 데이터 링크 계층과 유사
인터넷 계층(Internet Layer)
IP(Internet Protocol)를 사용하여 목적지까지 데이터를 전달하는 기능을 담당
인터넷 주소를 부여(Addressing)기능과 최적의 경로를 탐색하는라우팅(Routing)기능을 제공
처음엔 간단하게 중간값부터 포인터 두 개를 사용해서 조합을 만들려고 했다. 정렬해서 중간 값 좌우를 보면 간단히 조합의 개수를 셀 수 있는데다가 모든 조합을 구하는 것이 아니라 조합의 개수를 찾는 것이기 때문에 중간 값의 좌우 개수를 곱해주면 되기 때문이다.
다만 간과한 것이 중간 값이 다양하게 나올 때마다 중간에 있는 중간 값을 찾아줘야 하는데 이 경우 find 함수를 쓰게 되면 시간복잡도가 O(n) 이다. 거기에 중간 값이 q 번만큼 나오기 때문에 최종 시간 복잡도는 정렬 + (find * 중간값 input) = O(n log n + n * q) 가 된다. n의 최대는 5만, q의 최대는 20만이기 때문에 곱하면 100억이 된다...
그래서 시간 복잡도를 줄이기 위해 값들과 함께 인덱스를 미리 unordered_map에 저장하는 방식을 사용했습니다. 해당 방식을 사용하면 find와 다르게 주어지는 중간 값으로 바로 인덱스를 찾을 수 있어 시간복잡도가 O(1)이 됩니다.
코드
오답 코드(투 포인터)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int n, q;
long long temp, m;
vector<int> fuel;
int cnt;
int init(){
ios::sync_with_stdio(false);
cin.tie(0); cout.tie(0);
cin >> n >> q;
fuel.resize(n);
for(int i = 0; i < n; i++){
cin >> fuel[i];
}
sort(fuel.begin(), fuel.end());
}
void question(int m){
int idx = find(fuel.begin(), fuel.end(), m) - fuel.begin();
if (idx >= n || fuel[idx] != m){
cout << 0 << "\n";
return;
}
cout << idx * (n - idx - 1) << "\n";
}
int main(){
init();
for(int i = 0; i < q; i++){
cin >> m;
question(m);
}
return 0;
}
정답 코드
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
int n, q;
cin >> n >> q;
vector<int> data(n);
for (int i = 0; i < n; ++i) {
cin >> data[i];
}
sort(data.begin(), data.end());
unordered_map<int, int> index;
for (int i = 0; i < n; ++i) {
index[data[i]] = i;
}
while (q--) {
int m;
cin >> m;
if (index.find(m) == index.end()) {
cout << 0 << "\n";
} else {
int median_idx = index[m];
if (m == data[0] || m == data[n - 1]) {
cout << 0 << "\n";
} else {
int left_cnt = median_idx;
int right_cnt = n - median_idx - 1;
cout << left_cnt * right_cnt << "\n";
}
}
}
return 0;
}
연관된 데이터를 메모리상에 연속적이며 순차적으로미리 할당된 크기만큼저장하는 자료구조입니다. 미리 할당하기 때문에 프로그램 실행 전에 크기가 고정된다는 특징이 있습니다.
정적 배열은 시작 메모리 주소만을 저장하고 그 외의 주소는 따로 저장 하지 않으며 그것들에 접근 하기 위해 Offset이라는 개념을 사용하여 그것들에 접근합니다.Offset은 첫번째 원소로 부터 얼마나 떨어진지를 말하며, 그를 비교하기 위해서 index가 0부터 시작 합니다.
장점
인덱스만 알고 있으면 조회를 빠르게 할 수 있어서 조회를 자주해야 되는 작업에서 많이 사용합니다.
인덱스만 알고 있다면 빠르게 조회가 가능합니다. (시간복잡도:(O(1))
단점
프로그램 시작 전 크기가 고정되므로 사용할 메모리보다 크기를 너무 크게 선언했을 경우 메모리 낭비나 추가적인 overhead가 발생할 수 있는 것이 단점입니다.
하나의 같은 자료형으로만선언이 가능하고 하나의 배열 내에 int, char등의 여러 자료형이 나올 수 없습니다.
배열의중간에 데이터를 삽입하거나 삭제하기 어려우며 이로 인해 데이터 이동이 필요할 수 있습니다.
특정 조건을 충족하는 값을 찾는 탐색은 상대적으로 느립니다. (시간복잡도:(O(n))
동적 배열(Dynamic Array / Linked List)
저장 공간이 가득 차는 경우 자동적으로 사이즈를 늘려 데이터를 추가 및 저장 할 수 있는 유동적인 자료구조입니다. 정적 배열의 한계를 극복하고자 고안되었으며 예상한 것보다 더 많은 수의 데이터를 저장하느라 선언된 배열의 크기를 넘어선 경우 기존의 크기보다 더 큰 배열을 선언하여 데이터를 옮긴 뒤 기존의 배열은 메모리에서 삭제합니다.
데이터 삽입
새로운 노드를 생성하고 그 노드에 삽입하고자 하는 데이터를 넣는다.
n - 1번째 노드에 접근하여 그것이 들고 있는 다음 노드의 주소 값을 생성한 노드의 다음 노드 참조로 한다.
n - 1번째 노드의 다음 노드 참조를 생성한 노드의 주소로 한다.
데이터 삭제
n - 1번째 노드의 다음 노드 참조를 n번째 노드의 다음 노드 참조로 변경한다.
n번째 노드의 메모리를 릴리즈 한다.
resizable array, arraylist, liked list, dynamicarray 모두 동적 배열을 의미 합니다.
C++에서는vector, Java에서는LinkedList로 구현되어있습니다.
장점
배열의 중간에 데이터를 삽입하거나 삭제하는 것이 가능하여 데이터의 접근과 할당이 빨라 메모리를 효율적으로 관리 할 수 있습니다.
배열의 크기가 고정되어 있지 않고 유동적이어서 프로그램의 실행 중에도 늘어나거나 줄어들 수 있습니다.
단점
n번째 노드를 접근하기 위해서는 n번째 노드 전의 모든 노드들에 접근 해야할 수 있기 때문에 느립니다.
필요한 것 이상의 메모리 공간을 할당받으므로 낭비되는 메모리 공간이 발생할 수 있습니다.
각각의 노드들이 다음, 이전 노드의 주소를 가지고 있어야 하기에 공간 복잡도를 많이 활용하여 비효율적입니다.
resize vs reverse
동적배열을 더 심화해서 알기 위해서 resize와 reverse의 함수 차이에 대해 알고 있으면 좋습니다. 이것들은 c++ 에서 vector에 사용할 수 있는 함수입니다.
resize와 reverse를 비교하기 위해 size와 capacity를 알아야합니다. size()가실제 벡터에 들어있는 원소의 크기를 리턴해 준다면 capacity는 얼마만큼의 원소가 들어갈 수 있는지를 나타내 줍니다.
reverse는 실제로 값을 넣는것이 아닌 앞으로 값을 넣을 자리를 만드는 함수라고 생각하면 됩니다. 해당 함수를 사용하는 이유는 불필요한 재할당을 막아주기 위해서입니다. 동적 배열은 프로그램 실행 중에 사이즈를 늘이거나 줄일 수 있는 만큼 재할당시에 필요한 것 이상의 메모리 공간을 할당해 줍니다.
다음은 배열에 할당을 하지 않았을 때와 100으로 할당했을 때의 reverse를 100으로 해줬을 때의 차이입니다.
재할당 시기
X
100
1
2
100
2
4
200
3
8
400
4
16
800
5
32
1600
6
64
3200
7
128
6400
8
256
12800
9
512
10
1024
11
...
10000 이상의 값을 할당하기 위해 reverse를 사용해서 할당을 해주면 8번의 재할당을 하지만 자동으로 재할당을 해줄 시에는 10번을 재할당해도 10000개의 공간이 생기지 않는 것을 볼 수 있습니다. 만약 10000개 이상의 값을 넣어야한다면 그때마다 재할당을 해줘야하기 때문에 필요없는 메모리가 사용될 것입니다.
resize를 사용하면 만약 resize 크기가 원래 사이즈보다 작다면 뒤쪽 원소들이 삭제(소멸자 실행)되고, 크다면 원소들이 뒤쪽에 삽입(생성자 실행)된다. 만약 공간이 필요하다면 공간을 재할당 받고 부족한 크기만큼 새 원소를 생성합니다. 이후에 새 배열에 기존 원소들 모두 복사한 뒤에 기존 원소들을 모두 삭제합니다.
벡터의 크기를 미리 지정하는 경우, 미리 할당된 메모리 크기만큼 공간을 확보할 수 있기 때문에 성능상 이점이 있을 수 있습니다. 여러 번 push_back()을 호출하는 것보다 한 번에 resize()를 사용하여 메모리를 미리 확보하는 것이 더 효율적일 수 있습니다.